Proof of Concept
Liman framework design
Overview
Liman is a powerful framework engineered to build scalable, reliable, and maintainable AI Agents. It achieves this through a declarative manifest approach and an extensible modular architecture.
The core idea behind Liman is to define agent structures using manifests that incorporate basic, reusable components. These components are easily pluggable and cover key areas such as:
- Declarative Approach: Emphasizing a declarative approach through YAML manifests, similar to Kubernetes, augmented with an overlay (kustomize-like) feature for flexible configuration and extension.
- Telemetry: For comprehensive monitoring, insights, and cost optimization (FinOps), leveraging open standards like OpenTelemetry (Otel) for distributed tracing and metrics.
- Authorization: For secure access control, supporting robust mechanisms such as service accounts, assuming roles, and fine-grained access control to manage permissions effectively.
- Protocols: To facilitate diverse communication needs and seamless integration with various systems, including MCP, HTTP, WebSocket, A2A and others
- Side Effects: For managing external interactions throughout the agent's lifecycle, enabling operations such as external API calls, database interactions, and other service integrations in a controlled and defined manner.
- Extensible State: For highly flexible data management, allowing agents to utilize any datastore and any data format required, ensuring adaptability to diverse operational needs.
Should this specification be widely adopted, it could foster a common ecosystem of reusable components for AI Agents, paving the way for an "Agents Store" where shared functionalities can be discovered and integrated across diverse projects.
YAML Manifests
Liman represents AI Agents as a Graph of Nodes, similar to frameworks like LangGraph. In this graph:
- Each Node acts as a computational unit with its own configuration and behavior.
- Edges define the flow of data between these nodes.
This entire structure is defined in a YAML manifest file (JSON is also supported), which explicitly describes nodes, their properties, and their interconnections. The manifest uses a declarative approach, much like Kubernetes manifests, and supports an overlay design (similar to Kustomize) for extending base manifests with additional configurations.
This declarative methodology enables the creation of language-agnostic AI Agents. The agent's logic is defined solely in the manifest, allowing its underlying implementation to be in any programming language. Think of it like OpenAPI specifications with custom code generation: the manifest can be used to generate code in various languages such as Python, JavaScript, Go, and others.
Liman currently supports three primary Node types: LLMNode, ToolNode, and Node.
LLMNode
An LLMNode encapsulates the logic for interacting with Large Language Models (LLMs). Its primary function is to define prompts, often for multiple languages.
kind: LLMNode
name: StartNode
prompts: # <- LanguageBundle
system:
en: |
You are a helpful assistant.
ru: |
Ты полезный помощник.
notes:
en: { notes }
tools:
- OpenAPI_getUserA core feature of Liman is the LanguageBundle, which is used to parse every text section within the manifests. LanguageBundle supports a fallback language. If text is not defined for a specific language, the system automatically uses the designated fallback language.
For example, in the LLMNode snippet above, if notes were not defined for ru, the en version would be used as a fallback. This mechanism applies to any text section, regardless of its depth.
Here's how LanguageBundle handles fallback language:
prompts:
system:
en: You are a helpful assistant.
notes:
intro:
en: Hello
ru: Привет
bye:
de: Auf WiedersehenIf en is set as the fallback language, the system would process the above into:
prompts:
system:
en: You are a helpful assistant.
ru: You are a helpful assistant.
de: You are a helpful assistant.
notes:
en:
intro: Hello
ru:
intro: Привет
de:
intro: Hello # Fallback applied for 'intro'
bye: Auf WiedersehenOverlays
Overlays extend base manifests with additional configurations. They allow you to define extra properties for a node, such as tools, prompts, and more. A common use case is defining different prompts for various languages.
Overlays are applied in a specific order, based on their directory level and file name. Consider the following structure:
specs/
└── start_node/
├── llm_node.yaml
└── langs/
├── en.yaml
├── ru.yaml
└── de.yamlGiven these manifest files:
# start_llm_node.yaml
kind: LLMNode
name: StartNode
tools:
- OpenAPI_getUser
# langs/en.yaml
kind: Overlay
to: LLMNode:StartNode
prompts:
system: |
You are a helpful assistant.
notes:
intro: Hello
bye: Goodbye
# langs/ru.yaml
kind: Overlay
to: LLMNode:StartNode
prompts:
system: |
Ты полезный помощник.
notes:
intro: Привет
bye: Пока
# langs/de.yaml
kind: Overlay
to: LLMNode:StartNode
prompts:
system: |
Du bist ein hilfreicher Assistent.
notes:
intro: Hallo
bye: Auf WiedersehenThese separate files would be merged into a single LLMNode manifest. Overlays are versatile and can be applied to any node type, not just LLMNode, to extend its properties.
ToolNode
A ToolNode defines the logic for LLM function calling. It specifies a tool's signature and associated prompts.
kind: ToolNode
name: GetUser
description: # <- LanguageBundle
en: Get user by ID
ru: Получить пользователя по ID
de: Benutzer nach ID abrufen
func: lib.tools.get_user # <- Function to call, would be imported during the parsing
arguments:
- name: user_id
type: string
description: # <- LanguageBundle
en: User ID to get
ru: ID пользователя для получения
de: Benutzer-ID zum Abrufen
triggers: # <- LanguageBundle, optional
en:
- Give me the user X
- What is the user X?
ru:
- Дай мне пользователя X
- Какой пользователь X?
de:
- Gib mir den Benutzer X
- Was ist der Benutzer X?
tool_prompt_template: # <- LanguageBundle, optional
en: |
Supported tools:
{name} - {description}
Examples that can trigger this tool:
{triggers}
ru: |
Поддерживаемые функции:
{name} - {description}
Примеры, которые могут вызвать эту функцию:
{triggers}
de: |
Unterstützte Werkzeuge:
{name} - {description}
Beispiele, die dieses Tool auslösen können:
{triggers}During parsing, this ToolNode allows for easy generation of the tool calling signature for the LLM, which is then provided to the func.
The triggers and tool_prompt_template fields are optional. However, they are highly useful for providing extra information about the tool and how it can be invoked.
When you link a ToolNode to an LLMNode, as shown below:
kind: LLMNode
name: StartNode
prompts:
system:
en: You are a helpful assistant.
tools:
- GetUserBy default, the LLMNode.prompts.system will automatically incorporate the tool_prompt_template for each tool to improve function calling accuracy
So, the system prompt for the English (en) language would be augmented as follows:
You are a helpful assistant.
Supported tools:
GetUser - User ID to get
Examples that can trigger this tool:
- Give me the user X
- What is the user X?This automatic integration also applies to other languages, ensuring consistent prompt enhancement across all supported locales.
OpenAPI → ToolNode Generation
One of Liman's powerful features is the ability to automatically generate ToolNode definitions from OpenAPI specifications. This means your existing REST APIs can become AI agent tools without writing custom integration code.
When developing chat systems, many organizations already have REST APIs that could be useful as tools. OpenAPI specifications contain all the needed information to generate a ToolNode and make it available to the agent.
Automatic Conversion
Here's how a simple OpenAPI endpoint gets converted. Given this OpenAPI specification:
paths:
/users/{userId}:
get:
operationId: getUserById
summary: Get user by ID
parameters:
- name: userId
in: path
required: true
schema:
type: string
description: The user's unique identifier
responses:
"200":
description: User informationIt automatically becomes this ToolNode:
kind: ToolNode
name: OpenAPI__GetUserById
description:
en: Get user by ID
func: liman_openapi.gen.id_4341576960.getUserById # Auto-generated function by SDK
arguments:
- name: userId
type: str
required: true
description:
en: The user's unique identifierExtending Generated Tools
The generated ToolNode can be extended using overlays to add additional functionality:
kind: Overlay
to: ToolNode:OpenAPI__GetUserById
strategy: merge
nodes:
- target: OpenAPIErrorHandler
when: status_code != 200This approach eliminates the need to manually create MCP servers or write custom tool definitions, significantly accelerating the development of AI agents that integrate with existing APIs.
Condition Expression Language (DSL CE)
One of Liman's most powerful features is DSL CE (Domain Specific Language Condition Expression) - a custom language for defining intelligent flow control between nodes. Rather than writing repetitive conditional logic in code, you can express complex routing decisions declaratively in YAML.
Declarative Flow Control
CE DSL allows you to define when transitions between nodes should occur using expressive conditional statements:
nodes:
# Simple condition
- target: SuccessHandler
when: status == 'complete'
# Complex logical expressions
- target: RetryHandler
when: failed and (retry_count < 3 or priority == 'high')
# Function references for custom logic
- target: CustomValidator
when: business_rules.validate_transaction
# Built-in functions
- target: ErrorHandler
when: $is_error('UnauthorizedError') or $is_error('TimeoutError')
# Context-aware routing
- target: HighPriorityPath
when: user.tier == 'enterprise' and (urgent == true or customer_complaint == true)Supported Operators and Functions
CE DSL provides a rich set of operators and built-in functions:
Comparison Operators
==,!=: Equality and inequality>,<,>=,<=: Numerical comparisons- String and type-aware comparisons
Logical Operators
and/&&: Logical ANDor/||: Logical ORnot/!: Logical NOT- Parentheses for grouping:
(condition1 and condition2) or condition3
Built-in Functions
$is_error(error_type): Check for specific error types$now(): Current timestamp for time-based conditions
Function References
CE DSL can call external functions for complex business logic:
nodes:
- target: ApprovalRequired
when: business_rules.requires_approval
- target: AutoProcess
when: validation.is_safe_transactionContext Variables
CE DSL has access to rich context information:
- Node Results: Access outputs from previous nodes
- User Data: User profile, permissions, session information
- System State: Current system status, configuration values
- Request Context: Incoming request data, headers, metadata
Expression Evaluation
CE DSL expressions are evaluated at runtime with full access to the current execution context. This allows for dynamic routing based on:
- Data-driven decisions: Route based on content analysis
- User-specific flows: Different paths for different user types
- Error handling: Sophisticated error recovery strategies
This approach transforms static agent definitions into dynamic, intelligent systems that can adapt their behavior based on runtime conditions and context.
Execution model
Overview
The execution model consists of three main components:
- NodeActor manages role assumption, state, and node wrapping
- Launcher handles execution context creation, resource management, and NodeActor lifecycle
- Executor focuses purely on graph traversal, CE DSL evaluation, and flow control
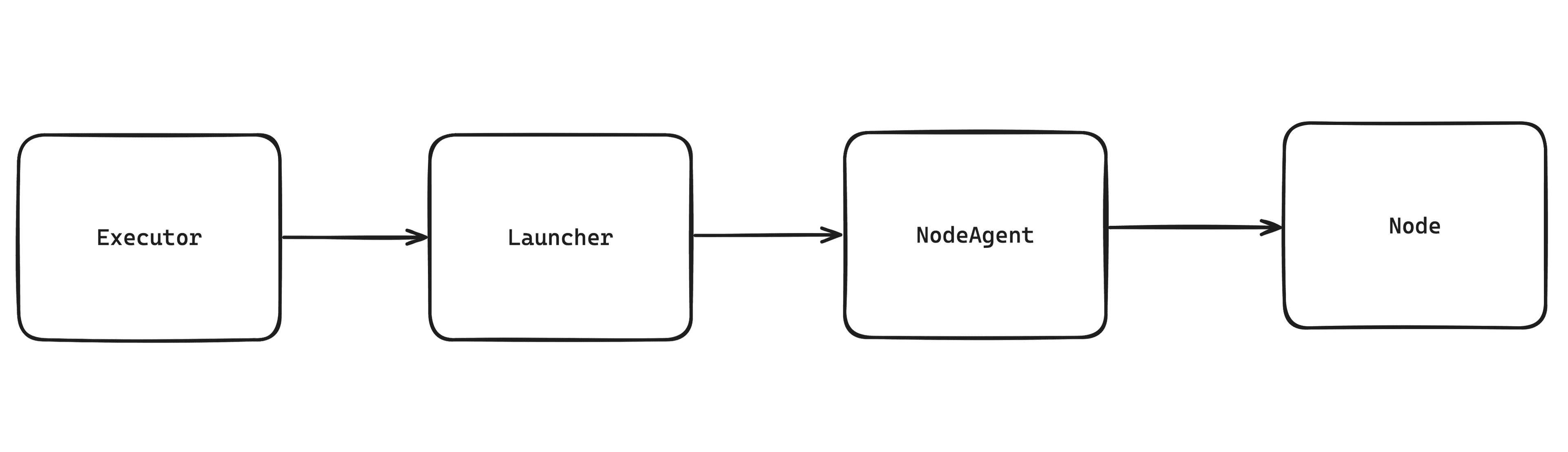

Executor -> Launcher -> NodeActor -> NodeDeveloper can work with Liman at any level: Node, NodeActor, Launcher, or Executor, depends on it's needs and required customization.
NodeActor
In Liman, every node is executed by its own dedicated NodeActor with limited scope and authorization. This isolation ensures security, resource control, and fault tolerance across distributed agent systems. Each node runs within its own execution context, similar to how containers isolate processes in containerized environments. The NodeActor is an internal component that wraps each node's execution.
Authorization Scoping
Each NodeActor operates with minimal required permissions defined at the node level. The authorization system is built around role assumption and credential provisioning to ensure secure access to external resources.
ActorNode Role Assumption
When a NodeActor needs to execute a node, it can assume specific roles required for that operation. This follows the principle of least privilege - each node only gets the permissions it absolutely needs.
For example, a user lookup tool would only assume a "user-data-reader" role with read permissions for user data, while a ticket creation tool would assume a "ticket-creator" role with write permissions only for the ticketing system.
CredentialsProvider Integration
The CredentialsProvider is responsible for supplying the necessary credentials when a NodeActor assumes a role. This abstraction allows for flexible credential management across different environments and services.
For OpenAPI calls, the CredentialsProvider automatically provides the appropriate authentication headers based on the assumed role and target service.
For example, when a ToolNode makes an OpenAPI call to retrieve user data, the NodeActor assumes the "user-data-reader" role, and the CredentialsProvider automatically injects the required Bearer token into the HTTP request headers.
Dynamic Credential Resolution
The CredentialsProvider resolves credentials dynamically based on the assumed role and target service:
- API calls: Provides Bearer tokens, API keys, or OAuth credentials
- Cloud services: Delivers service account tokens or IAM role credentials
This approach ensures that sensitive credentials are never hardcoded in manifests and are only provided to NodeActors that have explicitly assumed the necessary roles.
Launcher
The Launcher serves as the execution context manager, responsible for creating and managing NodeActors in different execution environments. It provides a clean abstraction layer between graph orchestration (handled by the Executor) and actual node execution, enabling flexible deployment across various compute contexts.
Architecture Design
The Launcher pattern follows the Executor + Launcher architecture:
Launcher Types
Liman supports multiple launcher implementations, each optimized for different execution contexts:
AsyncLauncher: Designed for high-concurrency I/O-bound operations using async/await patterns. Ideal for API calls, database queries, and LLM inference with low memory overhead and shared memory space for fast data exchange.
ThreadLauncher: Optimized for I/O-bound operations requiring thread-level isolation while maintaining shared memory access.
ProcessLauncher: Built for CPU-intensive tasks requiring complete process isolation and parallel processing capabilities. Essential for machine learning model inference, data processing, computational algorithms, and security-sensitive operations requiring strict isolation.
DistributedLauncher: Future implementation for distributed execution across multiple machines, containers, or cloud functions, enabling unlimited horizontal scalability.
Dynamic Selection and Resource Management
Launchers provide intelligent selection based on node characteristics and runtime conditions. The system can route different node types to appropriate execution contexts - LLM nodes to async launchers for I/O efficiency, CPU-intensive nodes to process launchers for parallel execution, and secure operations to isolated process launchers.
Implementation Benefits
The Launcher abstraction allows the Executor to remain focused on graph orchestration while delegating execution concerns to appropriate launcher implementations. This clean separation enables flexible deployment strategies, from simple single-threaded execution to complex distributed systems, all while maintaining consistent behavior and comprehensive observability.
Executor
The Executor is the orchestration engine that processes agent workflows through pure graph orchestration. It focuses exclusively on graph traversal, CE DSL evaluation, and flow control while delegating actual node execution to Launchers. This clean separation allows the Executor to remain focused on workflow logic while Launchers handle execution context management.
Execution Modes
The Executor supports flexible execution approaches:
- Full Graph Traversal: Process entire agent graphs following CE DSL edge conditions
- Subgraph Execution: Start execution from any node for workflow resumption
Parallel Execution & Synchronization
The Executor supports sophisticated parallel execution patterns:
- Fan-out: Automatically launch multiple nodes in parallel when CE DSL conditions allow concurrent execution
- Dependency Management: Track node dependencies and ensure execution order compliance
- Sink Operations: Wait for all parallel branches to complete before proceeding to dependent nodes
- Selective Synchronization: Continue execution as soon as required dependencies finish, without waiting for all parallel branches
This enables complex execution patterns where independent operations run concurrently while dependent operations wait for their prerequisites to complete.
Smart Edge Traversal
The Executor uses CE DSL to intelligently determine execution paths, evaluating conditions at runtime based on node results, context, and system state.
Built-in Resilience
- Fault Isolation: Node failures don't crash the entire graph
- Retry Policies: Configurable retry logic for transient failures
- Circuit Breakers: Prevent cascading failures in distributed scenarios
- Graceful Degradation: Continue execution when non-critical nodes fail
This separation of concerns between Executor (graph orchestration) and Launcher (execution context) allows Liman agents to scale seamlessly from simple applications to complex distributed systems while maintaining clean architecture, consistent behavior, and comprehensive observability.
Authientication & Authorization
Liman provides a robust authentication and authorization system built around the ServiceAccount specification. This system ensures secure access control and follows the principle of least privilege, where each node only gets the permissions it absolutely needs.
ServiceAccount
A ServiceAccount defines the authentication and authorization context for node execution. It provides credentials and context variables that nodes need to access external services and resources.
kind: ServiceAccount
name: MyServiceAccount
context:
strict: true
inject:
- user_id: user.id
- organization.id
credentials_provider: GCPCredentialsKey Components
Context Variables
The context field allows you to inject specific variables from the external state into the service account. This enables fine-grained control over what data is available to each node.
Context Configuration
strict: Iftrue, throws an error if a required variable is not found in the state (default:true)inject: List of variables to inject into the service account context
Variable Injection Formats
- Direct notation:
organization.id- accessed ascontext.organization.id - Custom assignment:
user_id: user.id- accessed ascontext.user_id
Example context configuration:
context:
strict: true
inject:
- user_id: user.id # Custom name assignment
- organization.id # Direct path
- project.settings.regionCredentials Provider
The credentials_provider (or credentials_providers for multiple providers) specifies how authentication credentials are obtained. These are phantom specifications - not declared in YAML but provided to the registry during runtime.
Single Provider
credentials_provider: GCPCredentialsMultiple Providers
credentials_providers:
- GCPCredentials
- AWSS3CredentialsNode Authz
Service accounts can be attached to nodes through the auth field, enabled by the built-in AuthPlugin.
NodeActor execution is scoped to the service account, ensuring that nodes only have access to the permissions defined in their associated service account.
kind: LLMNode
name: SecureLLMNode
prompts:
system: You are a helpful assistant.
auth:
service_account: MyServiceAccountInlined ServiceAccounts
ServiceAccounts can be declared inline within node specifications, eliminating the need for separate ServiceAccount manifests:
kind: ToolNode
name: UserLookupTool
description:
en: Look up user information
auth:
# Inlined ServiceAccount
service_account:
context:
inject: [user_id]
credentials_provider: UserDataCredentialsRuntime Integration
NodeActor acts as a selected ServiceAccount (based on DSL CE) and executes a node, what ensures that:
- State Isolation - context variables are extracted from external state in a controlled manner, ensuring only necessary data is exposed to nodes.
- Credential Provisioning - the CredentialsProvider supplies necessary credentials
- API calls: Bearer tokens, API keys, OAuth credentials
- Cloud services: Service account tokens, IAM role credentials
- Minimal Permissions - each ServiceAccount provides only the minimum required permissions for its associated node, following the principle of least privilege.
Plugins System
Liman's Plugin System enables dynamic extension of node specifications without hardcoding functionality. This allows users to add custom logic (such as authentication, monitoring, or custom behaviors) to any node type through a clean, declarative API. It helps maintain simple declarations while allowing extension to complex use cases.
Core Architecture
The plugin system is built around three key components:
- Plugin Registry: Central registration point for all plugins
- Plugin Protocol: Standard interface all plugins must implement
- Dynamic Schema Enhancement: Runtime modification of node specifications
Built-in Plugins
- AuthPlugin - Liman includes a built-in authentication plugin that adds
authfields to all node types
This enables authentication configuration in YAML manifests:kind: Node name: SecureNode prompts: system: en: You are a helpful assistant. auth: service_account: context: inject: [user_id, org_id] credentials_provider: GCPCredentials
Python
Plugin Interface
Every plugin must implement the following interface:
from typing import Any, Protocol
from abc import abstractmethod
class Plugin(Protocol):
@property
@abstractmethod
def name(self) -> str:
"""Unique plugin identifier"""
...
@property
@abstractmethod
def applies_to(self) -> list[str]:
"""List of spec types this plugin extends (e.g., ['Node', 'LLMNode'])"""
...
@property
@abstractmethod
def field_name(self) -> str:
"""Field name added to specifications"""
...
@property
@abstractmethod
def field_type(self) -> type:
"""Field structure type (e.g., Pydantic model in python)"""
...
@abstractmethod
def validate(self, spec_data: Any) -> Any:
"""Validate and transform plugin-specific data"""
...Plugin Registration
Plugins are registered before node specifications are imported, enabling runtime schema enhancement
register_plugins([
AuthPlugin(),
MCPPlugin(),
A2APlugin(),
])Example
In this example, we create a custom plugin for adding metrics to nodes. This plugin can be applied to specific node types like LLMNode or ToolNode, allowing users to define metrics configurations directly in their YAML manifests.
from typing import Any
from pydantic import BaseModel
from liman_core.plugins.registry import Plugin
class MetricsSpec(BaseModel):
enabled: bool = True
custom_tags: dict[str, str] = {}
alert_thresholds: dict[str, float] = {}
class CustomMetricsPlugin:
name = "custom_metrics"
applies_to = ["LLMNode", "ToolNode"] # Only specific node types
field_name = "metrics"
field_type = MetricsSpec
def validate(self, spec_data: Any) -> MetricsSpec:
return MetricsSpec(**spec_data) if spec_data else MetricsSpec()Usage in YAML:
kind: LLMNode
name: StartNode
prompts:
system: You are a helpful assistant.
metrics:
enabled: true
custom_tags:
team: ai-platform
environment: production
alert_thresholds:
response_time: 2.0
error_rate: 0.05Plugin Composition
Multiple plugins can extend the same node type, creating rich, composable specifications:
kind: ToolNode
name: EnhancedTool
description:
en: Enhanced tool with multiple plugin extensions
# builtin AuthPlugin
auth:
service_account: ToolServiceAccount
# CustomMetricsPlugin
metrics:
enabled: true
custom_tags:
priority: high
# RateLimiterPlugin
rate_limiter:
requests_per_minute: 60
burst_limit: 10Benefits
- Extensibility: Add any custom functionality without modifying core specifications
- Composability: Multiple plugins can enhance the same node type
- Clean Separation: Core specs remain focused, plugins handle specialized concerns
This plugin architecture enables the Liman ecosystem to grow organically, with community-contributed plugins for authentication, monitoring, security, compliance, and specialized domain logic.
To Be Continued...
This specification is actively being developed. More sections covering advanced features, implementation details, and practical examples will be added soon.
Stay tuned for updates on distributed state management, observability patterns, and real-world deployment scenarios.
Last updated on